В чем разница: Просто QA, QA с AI-инструментами и AI QA?
Перестаньте говорить о AI тестировании, если речь идет всего лишь об использовании ChatGPT для написания скриптов. 🛑
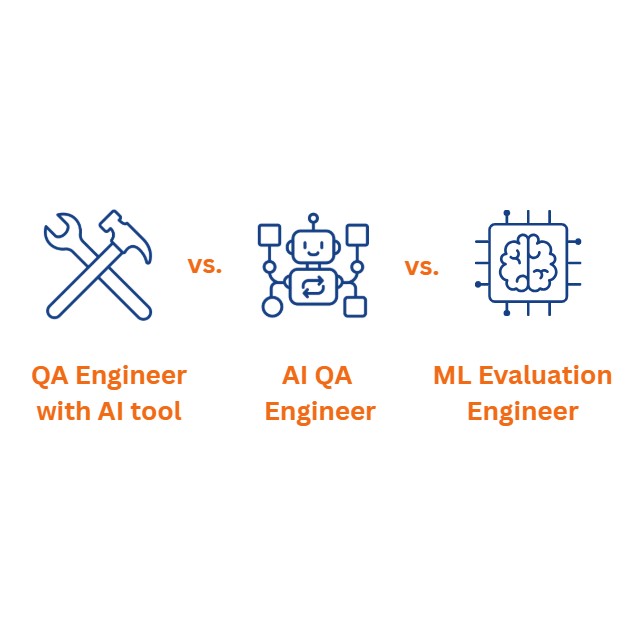
На рынке сейчас возникла большая путаница с определением трех абсолютно разных ролей. Если вы нанимаете людей или ищете работу, нужно понимать разницу между ними.
1. QA инженер, вооруженный AI-инструментами
Цель: Эффективность
Реальность: Тестирует традиционный детерменированный продукт. Использует ChatGPT для генерации тестов или Cursor/ClaudeCode для автоматизации — т.е. просто вайб-кодит для ускорения, но задачи остаются «олд-скульными»
2. QA инженер, тестирующий встроенную AI функциональность
Цель: Интеграционное тестирование, где на одной из сторон находится LLM.
Реальность: Может, например, проверять, как LLM-chat работает с тестируемой CRM-системой, достаточно ли вежлива модель или как часто она галлюцинирует. Уже интереснее, хотя тестер все еще использует традиционные ассерты и прочие подходы.
3. AI QA (ML evaluation инженер)
Цель: Упорядочивание недерменированного хаоса 🙂
Реальность: Вместо ассертов — статистические метрики и пороговые значения.
Инструменты: Evaluation harness (вроде EleutherAI), специальные питоновские библиотеки.
Почему третий вариант отличается от двух предыдущих?
- Вероятность против детерминизма. Вы не проверяете, что 2+2=4. Вы проверяете, что значение метрики 0.87 достаточно для вашего специфического случая.
- Тестирование стоимости: Потраченные токены приобретают важнейшее значение. Если ваш агент «умный», но стоит $2 за запрос, тест провален.
- Скорость из дополнительной характеристики становится основной. На современном рынке быстрая модель 7B часто лучше медленной модели 70B.
Итог
Традиционное QA — ищем баги.
ML evaluation — измеряем вероятности.